MPP Scheduling
This section describes MPP scheduling flows, task types and their usage in SOF based on Zephyr API.
MPP Scheduling defines four task categories:
Low Latency audio data processing tasks (LL) - high priority,
Tasks with Budget (TwB) - medium priority,
audio Data Processing tasks (DP) - low priority,
background (idle) priority tasks
NOTE: As of today, only LL tasks has been integrated with Zephyr. TwB, DP and idle tasks are work in progress (WIP).
The role of MPP Scheduling is limited to task threads definition, configuration and state management. The thread scheduling itself is handled by Zephyr.
MPP Scheduling is designed to:
address strict real-time requirements,
i.e. to avoid under/overflows on isochronous interfaces such as I2S,
provide predictable latency,
reduce amount of buffering needed,
MPP Scheduling defines two tasks categories:
Task categories characteristic:
LL tasks for latency sensitive audio data processing,
LL tasks are organized in queues shared between component instances,
there is one non-preemptive high priority LL Thread assigned to exactly one core. For example, for HW configuration with 4 cores there will be 4 LL Threads,
each queue is statically linked to one LL Thread and all queue tasks will be processed on a core that LL Thread is assigned to,
there are multiple queues per LL Thread which represent a priority and guarantee tasks execution order,
TwB for medium priority processing (e.g., IPC/IDC message handling),
each TwB is scheduled as a separate preemptive thread,
TwB has assigned budget for processing that is refreshed in each sys tick (Zephyr Thread time slicing),
TwB priority is dropped to low when budget is consumed,
DP tasks for low priority audio processing,
DP tasks are scheduled based on earliest deadline first (EDF) algorithm,
each DP task is scheduled as a separate preemptive thread,
DP tasks can be assigned to one of the available cores,
idle tasks for background processing,
idle tasks are scheduled as separate preemptive threads,
they have the lowest priority and are scheduled when all other tasks completed their processing,
they are used in Fast Mode. For example, in data draining from firmware to host.
NOTE: Each task is assigned by MPP Scheduling to one core. Tasks are executed by the assigned core till termination.
NOTE: For Earliest Deadline First (EDF) algorithm description, please refer to link: Wikipedia.
NOTE: For Zephyr Scheduling description, please refer to link: Zephyr Scheduling.
Figure 45 SOF MPP Scheduling based on Zephyr
LL Tasks
Low Latency Tasks are executed within one of the non-preemptive high priority LL Threads that runs all ready-to-run tasks till completion during a single cycle. There is one LL Thread scheduled per core with its own queues and LL tasks to execute.
MPP Scheduling adds ready tasks to LL queues at the beginning of each scheduling period. There are a number of queues to add tasks to. LL Thread iterates over the queues, and runs all tasks from one queue before moving to the next queue. Therefore, it is possible to guarantee that some tasks are always run before others during a cycle.
There are also two special queues: pre-run queue and post-run queue. Tasks from pre-run queue are run at the beginning of each cycle (may consider them to have the highest priority).
Tasks from post-run queue are run at the end of each cycle (may consider them to have the lowest priority).
Example of a pre-run task may be a task registered by the sink driver that starts the sink at the very beginning of the cycle if data was supplied during the previous cycles and link has been stopped.
DP Tasks
The data processing components are represented as a DP tasks that are scheduled as separate preemptive threads. DP threads scheduling is done according to EDF (Earliest Deadline First) algorithm that is part of Zephyr.
To meet real-time processing criteria algorithm operates by choosing component task that is closest to its deadline (time when output data is required).
For playback case algorithm starts from sink and going backward calculates deadline for data delivery:
Time required by component to process data depend on processing period and compute.
Goal is to process data through chain before real-time sink deadline
EDF scheduling example
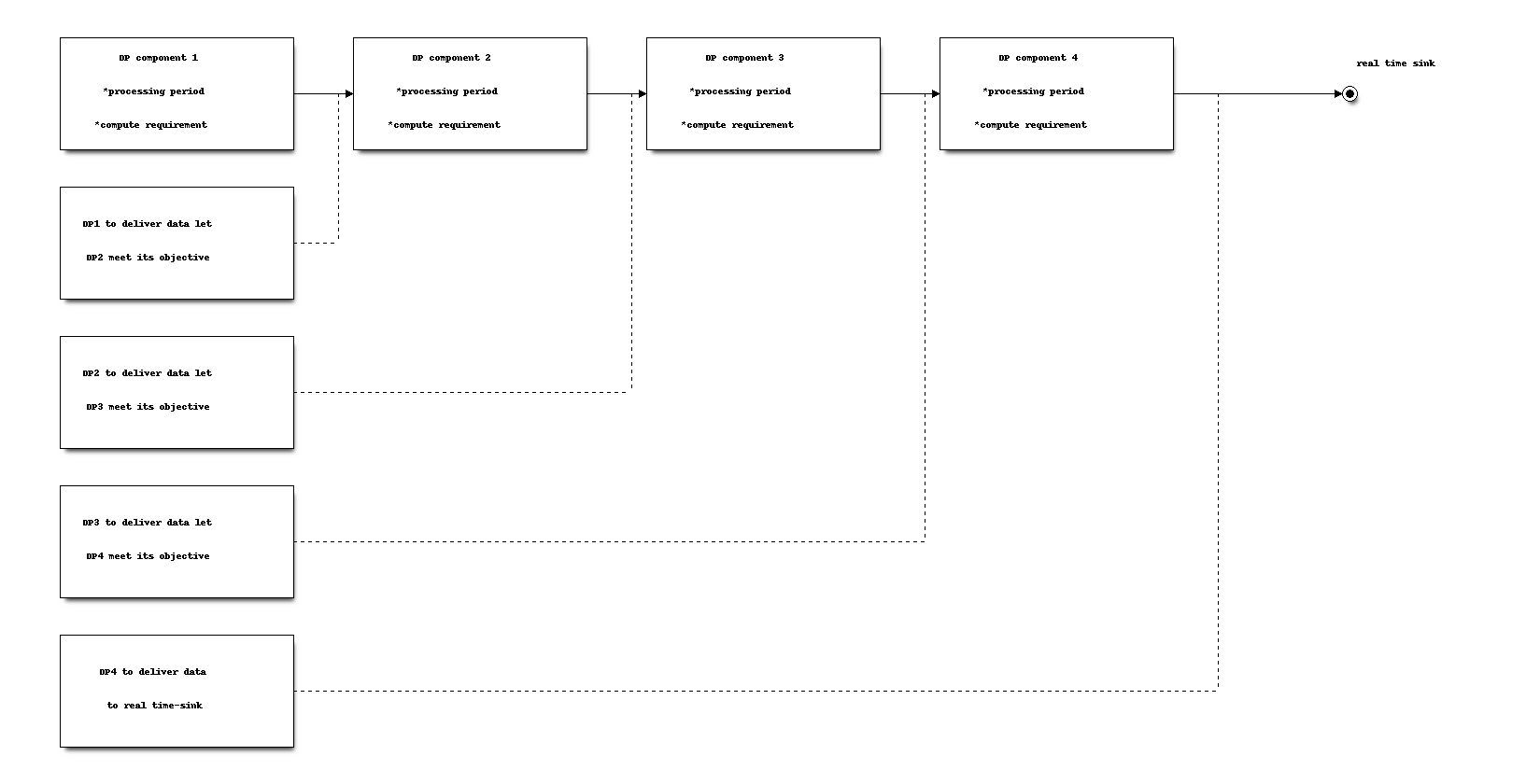
The capture pipelines operate in the same way.
It is important to consider that EDF assumes preemptive scheduling of the DP Tasks and lack of dependency between them.
Task With Budget
This is a specialized version of DP task that has pre-allocated MCPS budget renewed with every system tick. When the task is ready to run, then depending on the budget left in the current system tick, either MEDIUM_PRIORITY or LOW_PRIORITY is assigned to task thread. The latter allows for opportunistic execution if there is no other ready task with a higher priority while the budget is already spent.
Examples of tasks with budget: Ipc Task, Idc Task.
Task with Budget (TWB) has two key parameters assigned:
cycles granted: the budget per system tick,
cycles consumed: number of cycles consumed in a given system_tick for task execution
The number of cycles consumed is being reset to 0 at the beginning of each system_tick, renewing TWB budget. When the number of cycles consumed exceed cycles granted, the task is switched from MEDIUM to LOW priority. When the task with budget thread is created the MPP Scheduling is responsible to set thread time slice equal to task budget along with setting callback on time slice timeout. Thread time slicing guarantee that Zephyr scheduler will interrupt execution when the budget is spent, so MPP Scheduling timeout callback can re-evaluate task priority.
If there is a budget left in some system tick (task spent less time or started executing close to the system tick that preempts execution), it is reset and not carried over to the next tick.
NOTE The Zephyr Scheduler track time slice budget of the TWB when preempted and log warning if the budget is significantly exceeded (some long critical section inside the task’s code might be responsible for this).
NOTE The MPP Scheduling must be notified by TWB on processing complete and update cycles consumed in the current system tick. This allows to schedule TWB more than once (if necessary) in the single system tick with MEDIUM_PRIORITY. The second TWB schedule should be done with modified time slice value, equal to delta between budget and cycles consumed.
Scheduling flows
Zephyr scheduling
The presented Zephyr scheduling flow takes place on each core that has MPP tasks scheduled.
Figure 46 Zephyr scheduling of MPP threads flow
MPP Data Processing and Task with Budget threads periodic update
Zoom in to Data Processing (Earliest Deadline First) and Task with Budget Threads periodic update operations on each system tick start.
Figure 47 DP and TWB threads sys tick update flow
Task with budget scheduling
Figure 48 Task with budget example scheduling flow
Example timeline of MPP Scheduling on a DSP core
The below diagram shows how scheduling looks like on a DSP core. At the timer interrupt, LL scheduler runs as the first one and then DP scheduler is executed.
Figure 49 Example timeline of MPP Scheduling on DSP core with LL and DP tasks scheduling
Example timeline of DP tasks scheduling on secondary DSP core
The below diagram shows a detailed example of how DP tasks are scheduled on the secondary DSP core.
Figure 50 Example of DP tasks scheduling on secondary DSP core
Example timeline of MPP scheduling on multiple DSP cores
The below diagram shows how scheduling looks like on many DSP cores. The DP task deadlines are reevaluated on each core in Timer sys tick callback.
Figure 51 Example of MPP Scheduling on many cores - LL and DP tasks scheduling
Fast Mode
The Fast Mode is used to process data faster than real time. The processing faster than real time is only needed for a short time period and it happens i.e. when firmware performs low power Wake on Voice. In such case SOF firmware is working in low power mode, performing i.e. key phrase detection algorithm, accumulating last few seconds of audio samples in history buffer. When a key phrase detection happens, there is a need to stream the accumulated history to Host as quickly as possible with optional additional processing on DSP. It is only possible when a sink interface to Host transfer burst of data from DSP.
The Fast Mode is an idle low priority task. The task is only executed when other DP tasks with deadlines has completed their processing and there is still enough DSP cycles before a next system tick.
When the Fast Mode task is created by i.e. History Buffer, the component instance (i.e. History Buffer) needs to provide a list of LL component instances that will be executed within a Fast Mode thread, similar as it is done with LL tasks queues and LL Thread. When the Fast Mode thread is executed it will trigger processing of LL components in similar way as LL Thread does. The Fast Mode task is executed in the critical section. It will check if there is data available in an input queue and there is enough space in an output queue. Only then it will execute a LL component. What is important to note is that the Fast Mode task does not call processing on the DP components directly.
As described in the previous sections, the processing on DP components is called according to EDF algorithm. A periodicity of a component processing is determined by time needed to fill an input queue using real time source of data. When an input queue has sufficient amount of data, the processing on DP component can be called. The input queues for DP components that are on the Fast Mode task path will be filling much faster than real time as the side effect of the Fast Mode task execution - LL components will move data to DP component input queue and out of DP component output queue. As the result, DP component can be executed much earlier than real time - a DSP task reports “ready to run” as soon as it has sufficient amount of data in input queue and output queue has enough space for produced frame. That can lead to starvation of other tasks and to prevent it a Fast Mode tasks must be scheduled as idle tasks in background.
Watchdog timer
Depending on HW configuration there can be a single watchdog timer, watchdog available for each DSP core or none.
All DSP cores shall enable watchdog when they are active to monitor health of subsystem. When one of watchdogs will expire, the entire subsystem will be reset by Host.
Watchdog shall be enabled when:
DSP core is enabled,
tasks are assigned to DSP core,
Watchdog shall be disabled when:
DSP core is disabled,
no tasks are assigned to DSP core,
DSP core goes to low power state,
Watchdog timer shall be programmed to value of a few scheduling periods.
Watchdog timer when enabled shall be updated at every system tick. In case of primary DSP core, it should be after running LL tasks. In case of secondary HP DSP cores, it should be on system tick end.